Yesterday I presented at StanCon. This is the virtual poster I created for the conference, and here is a video talking about it:
My main message is the following:
Before doing any analysis, get an understanding of the decision that that you are trying to help people make. Do not present result with incredible certitude. That is, you should communicate the uncertainty in our findings. Do not follow the null hypothesis ritual blindly.
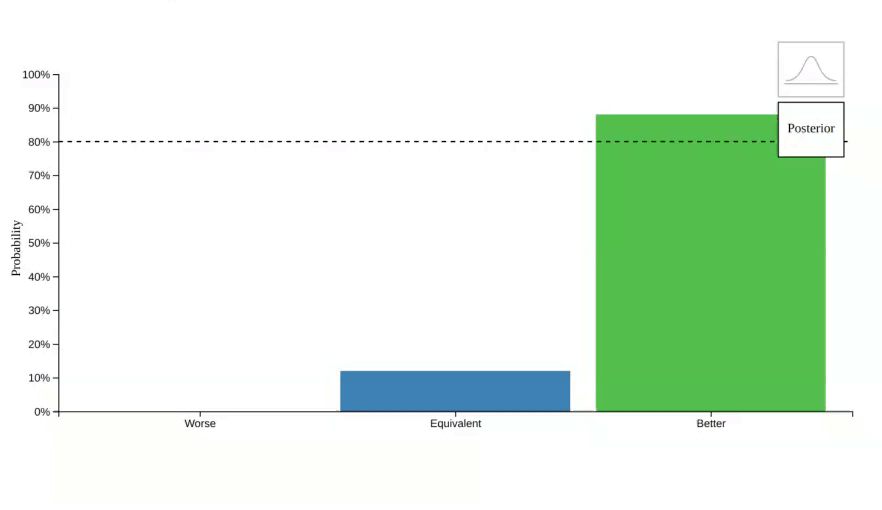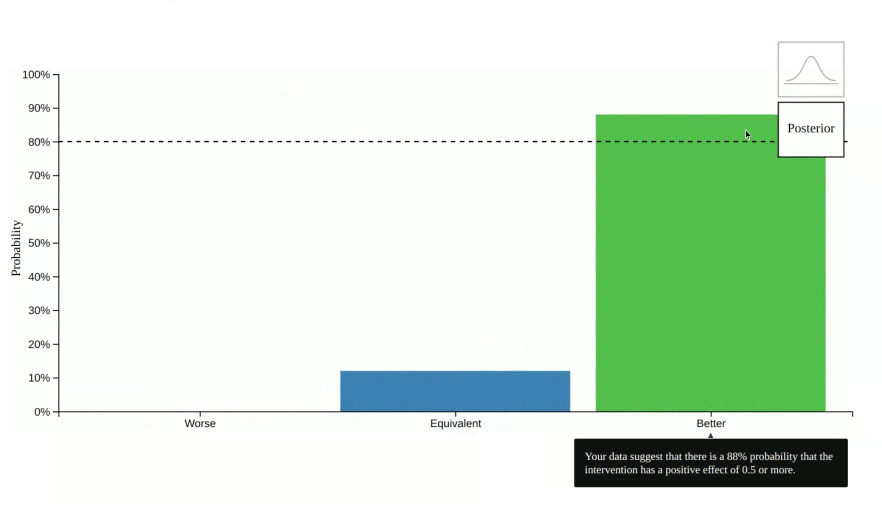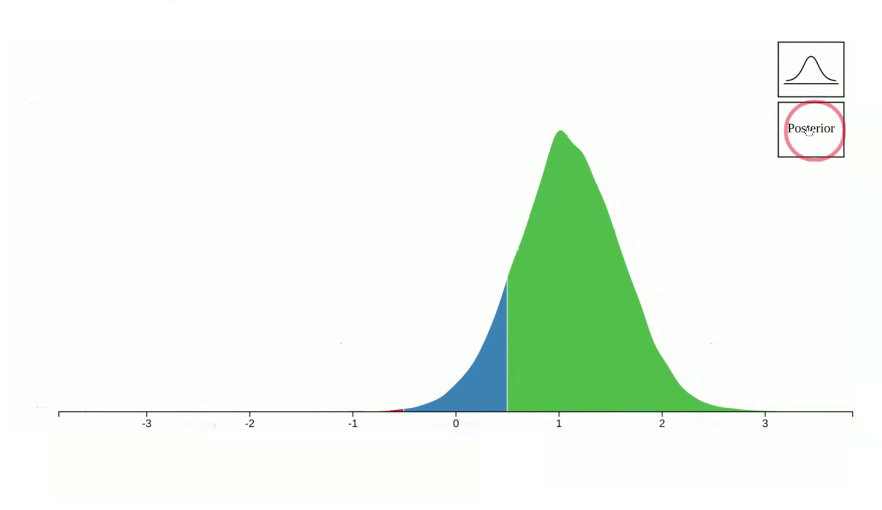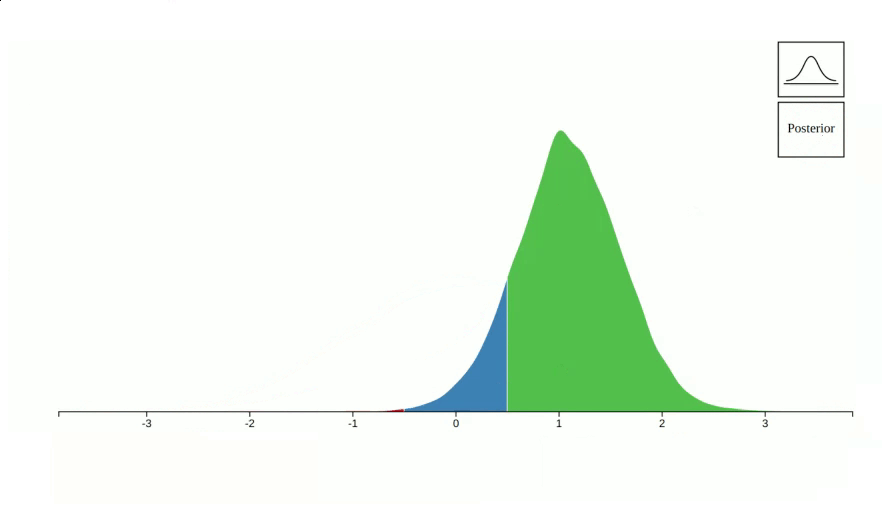
vizdraws is available on cran. The goal of this package is to help communicate findings in a better way. For example, instead of communicating a point estimate you can communicate the probability that something is better or worse that its alternative:
library(vizdraws) vizdraws(prior = 'normal(0.05, 0.2)', posterior = rnorm(n = 10000, mean = 0.3, sd = 0.5))
However, in some cases 0 is not a relevant threshold for decision making.
Why? Shiny will scale really well as the data is not duplicated in memory for each user The data is housed in one location (plumber API) The underlying data can be VERY large, which may not be suitable for a shiny app, but is ok for an R process to solve. The API inner workings can be updated without redeploying the shiny application. The docker-compose.yml version: '3.
Stan Map-Reduce Stan allows you to split your data into shards, calculate the log likelihoods for each of those shards, and then combine the results by summing and incrementing the target log density.
Stan’s map function takes an array of parameters thetas, real data x_rs, and integer data x_is. These arrays must have the same size.
Example This is a re-implementation of Richard McElreath’s multithreadign and map-reduce with cmdstan using Rstan instead of cmdstan.
Inspired by this thread I decided to document how you can use Stan on a AWS instance with remoter.
Creating an AMI The simplest way of doing this is to start with an Ubuntu VM and install a docker container with Remoter and Rstan. I wrote a simple bash script that does that. Just ssh into Ubuntu and run:
wget -O - https://link.ignacio.website/remoter | bash Now ssh back into the instance and modify the password in my docker-compose.
Quick how to: # drat::addRepo(account = "Ignacio", alturl = "https://drat.ignacio.website/") # install.packages("IMS3") library("IMS3") ## Loading required package: aws.s3 set.enviroment() bucketlist() ## c..ignacios.test.bucket....2019.03.19T13.21.52.000Z.. ## 1 ignacios-test-bucket ## 2 2019-03-19T13:21:52.000Z # save an in-memory R object into S3 s3save(mtcars, bucket = "ignacios-test-bucket", object = "mtcars.Rdata") # `load()` R objects from the file s3load("mtcars.Rdata", bucket = "ignacios-test-bucket") Video talking about this: Using S3 from within an EC2 instance I added the aws.
Why? I want to make sure that when I make a change to some complicated code nothing breaks. Moreover, I want to make sure that nothing breaks in a clean install.
Getting gitlab up and running If you are reading this you probably know that I like gitlab better than bitbucket, github, and that awfaul thing that you are probably using. You can skip this and the next section and just use the hosted version of gitlab which gives you 2000 minutes per month to do this stuff.
This is my list of resources for people that want to go Bayesian. This list is very incompleate and I plan to update it over the next couple of weeks.
Online videos and coursse What are Bayesian Methods? - OPRE in 60 Seconds Tiny Data, Approximate Bayesian Computation and the Socks of Karl Broman: Less than 20 minutes, and very easy to follow. Bayesian Regression Modeling with rstanarm: Very short and simple Ben Goodrich’s Bayesian Statistics for the Social Sciences: Semester long, totally worth it Videos Class material Richard McElreath’s Statistical Rethinking: Semester long, totally worth it Videos Class material Book Bayesian Data Analysis course - GSU 2023 Papers, books, vignettes, and blogs Bayesian data analysis for newcomers Speaking on Data’s Behalf: What Researchers Say and How Audiences Choose Why We (Usually) Don’t Have to Worry About Multiple Comparisons Visualization in Bayesian workflow Stan User’s Guide Bayesian Data Analysis Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan Data Analysis Using Regression and Multilevel/Hierarchical Models What works for whom?
The following code shows how to write some simple code to draw random numbers from a normal and a binomial distribution. Notice that instead of declaring A as a numeric matri
Serial Double loop #include <Rcpp.h>using namespace Rcpp; // [[Rcpp::export]] NumericMatrix my_matrix(int I) { NumericMatrix A(I,2); for(int i = 0; i < I; i++){ A(i,0) = R::rnorm(2,1) ; A(i,1) = R::rbinom(1,0.5) ; } colnames(A) = CharacterVector::create("Normal", "Bernoulli"); return A; } set.